- LeNet – 1998
- AlexNet – 2012
- ZFNet – 2013
- NiN – 2014
- GoogLeNet(Inception V1) – 2014
- VGGNet – 2014
- ResNet – 2015
- Inception V2和V3 – 2015
- Inception V4 – 2016
- Inception-ResNet v1
- Inception-ResNet v2
- SqueezeNet – 2016
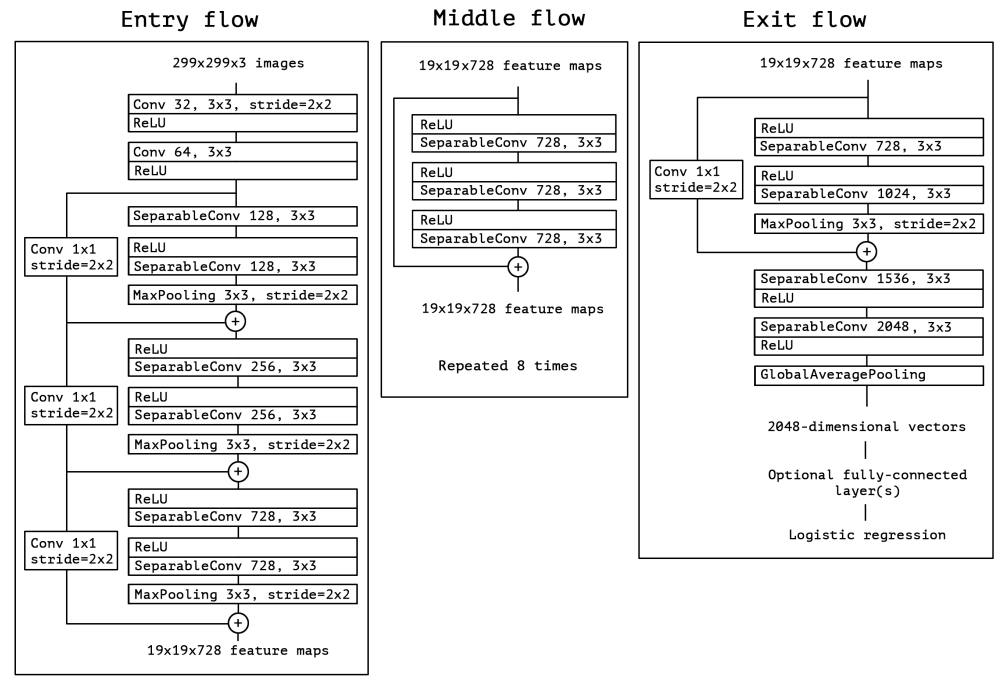
- Xception – 2017
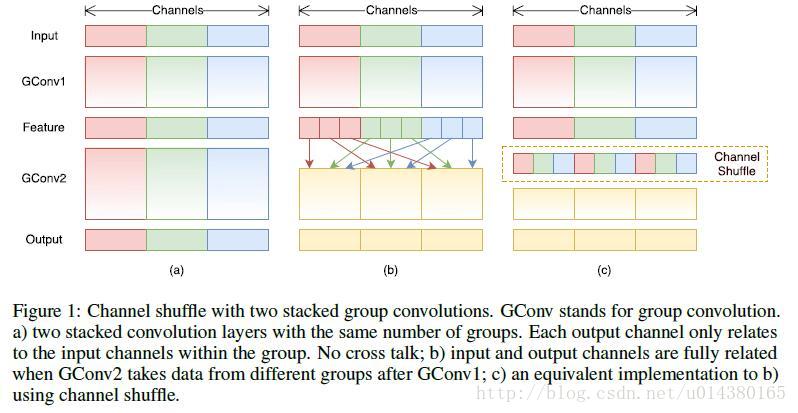
- ShuffleNet – 2017
- DenseNet – 2017
- SENet – 2017
- MobileNet V1 – 2017
- MobileNet V2 – 2018
- ResNeXt
- Res2Net
- MobileNet V3 – 2019
LeNet – 1998
网络结构如下所示:
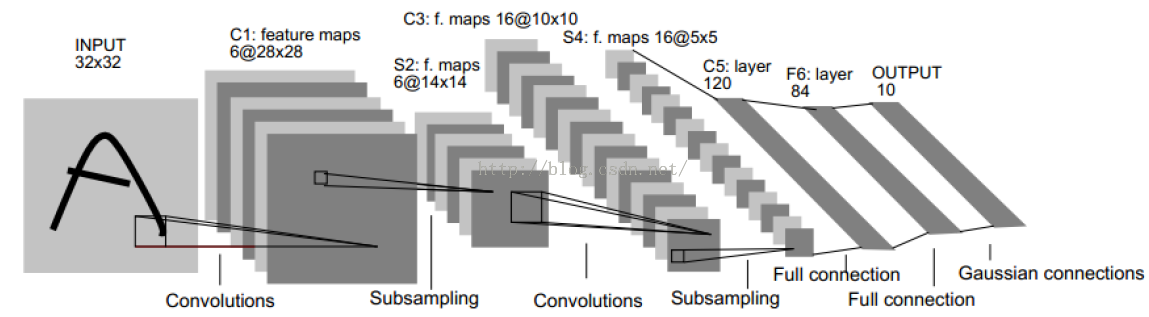
特点:
- 引入了卷积层
- 引入了池化层(平均池化)
- 非线性激活函数(tanh、sigmoid)
AlexNet – 2012
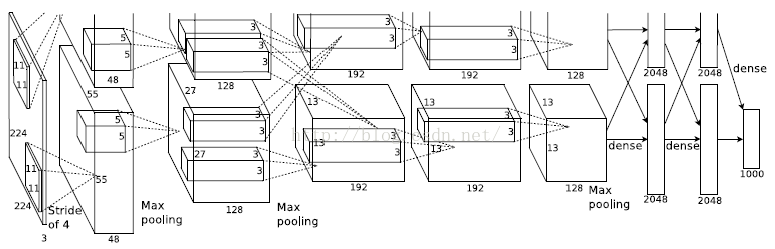
特点:
- 使用了ReLU
- 重叠的最大池化
- 使用了dorpout,数据增强
- 使用了多GPU
- 使用了LRN归一化层(激活的神经元抑制相邻神经元)
ZFNet – 2013
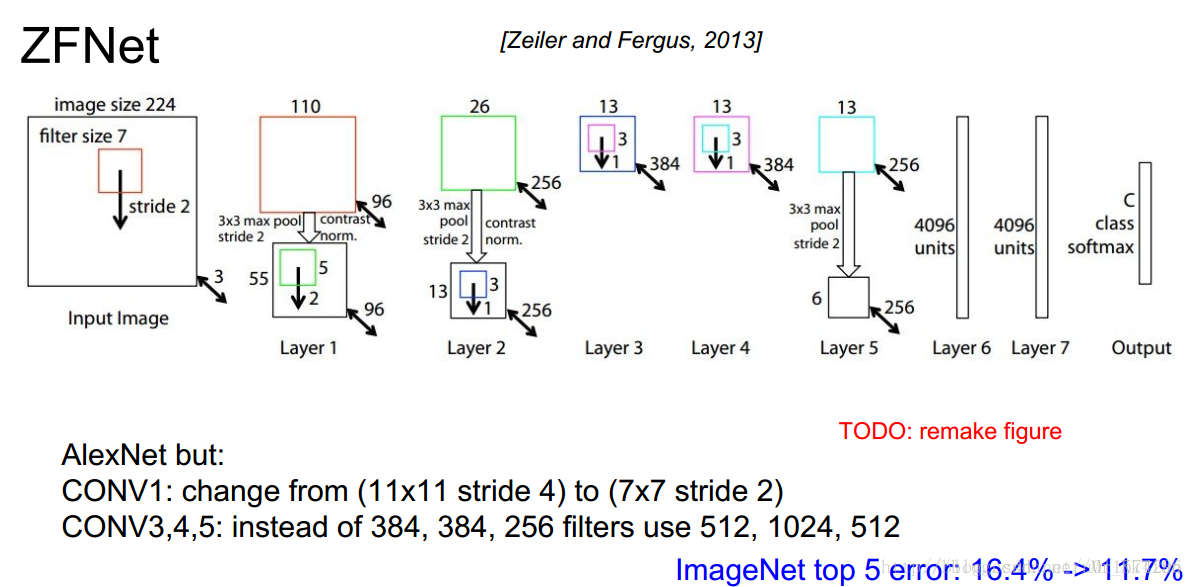
特点:
- 使用反卷积(Deconvnet)可视化特征图
- 使用了更小的卷积核和更小的步长
NiN – 2014
特点:
- 网络中间插入网络
- 提出全局平均池化(Global Average Pooling)代替全连接层
- 使用了$1*1$卷积层
- 使用了MaxOut
GoogLeNet(Inception V1) – 2014
Inception基本结构如下:
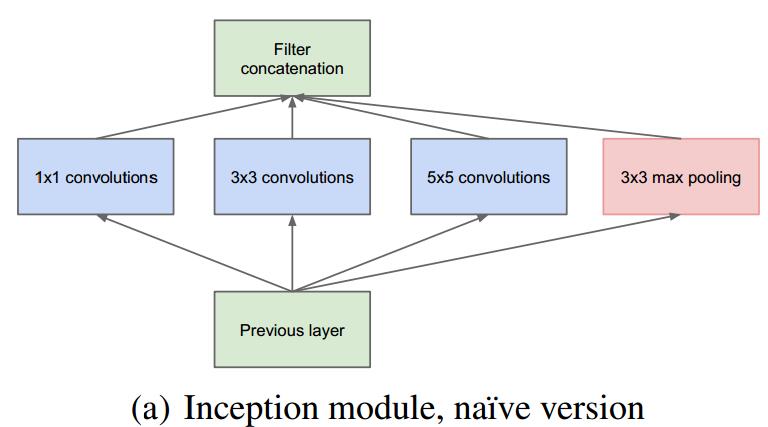
由于参数过多,借鉴NiN中$1 * 1$卷积后,改进为:
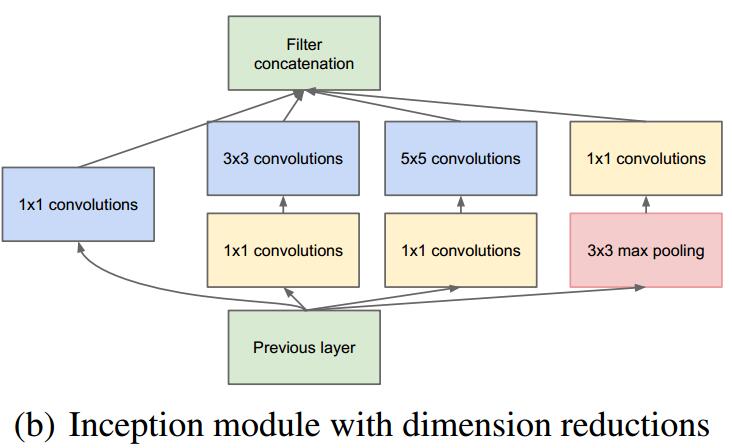
VGGNet – 2014
网络结构如下:
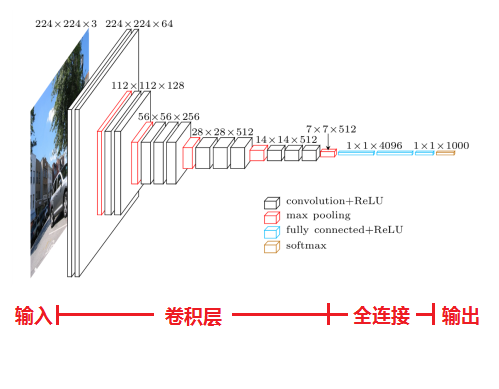
特点:
- 证明了LRN没用
- 证明了增加深度能提高性能
- 只用$3*3$卷积和$2*2$池化
ResNet – 2015
ResNet最初的结构如图:
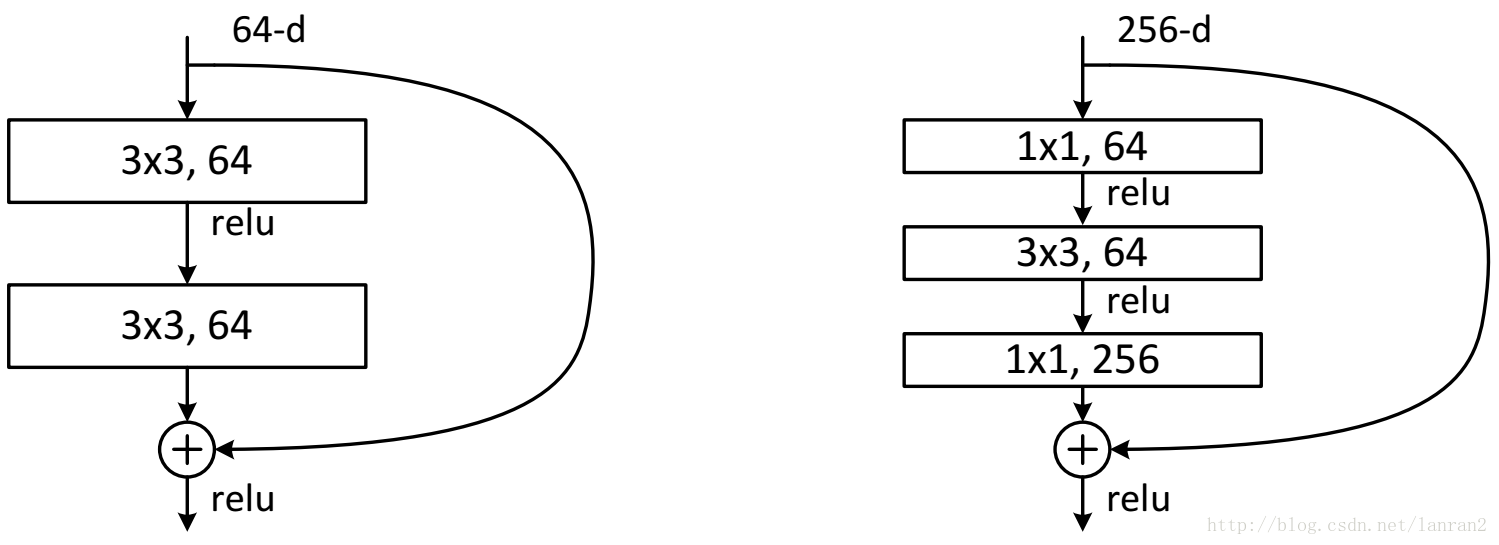
ResNet发展的各种变体:
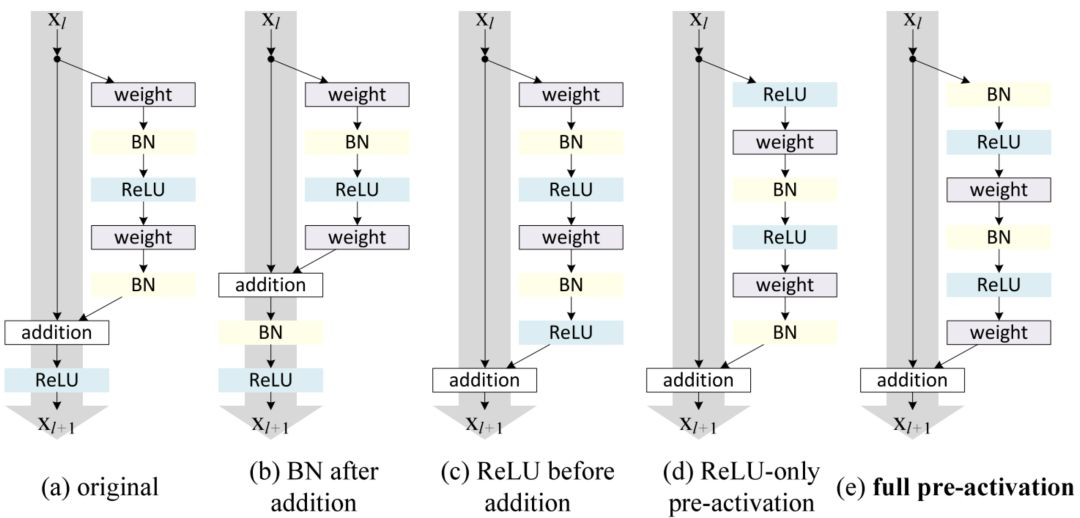
Inception V2和V3 – 2015
v2: 将$5*5$卷积换成两个$3*3$卷积,引入BN层
v3: 将$n*n$卷积换为$1*n$和$n*1$卷积
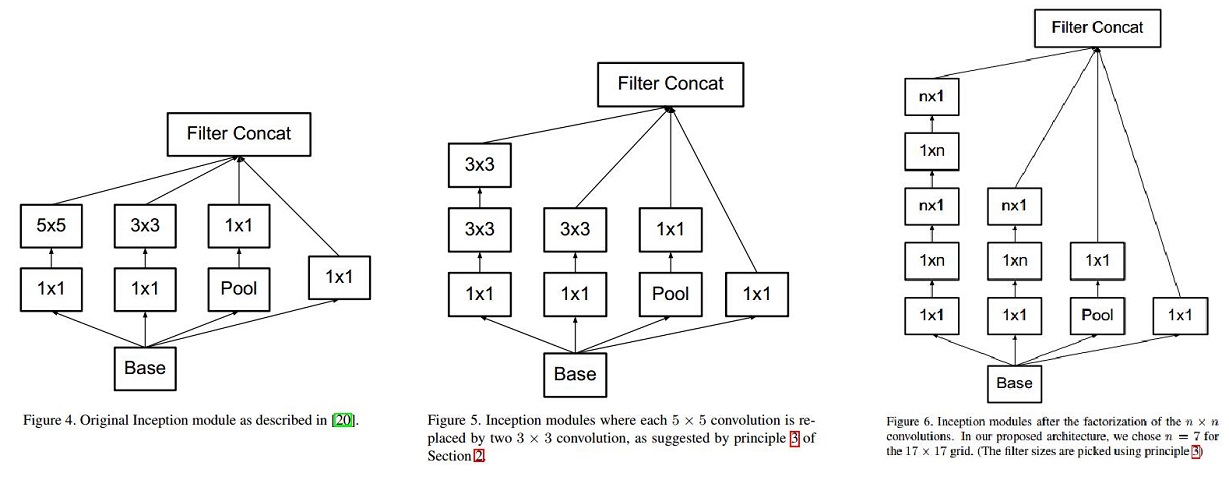
Inception V4 – 2016
使用了不同的Inception块,具体如下:
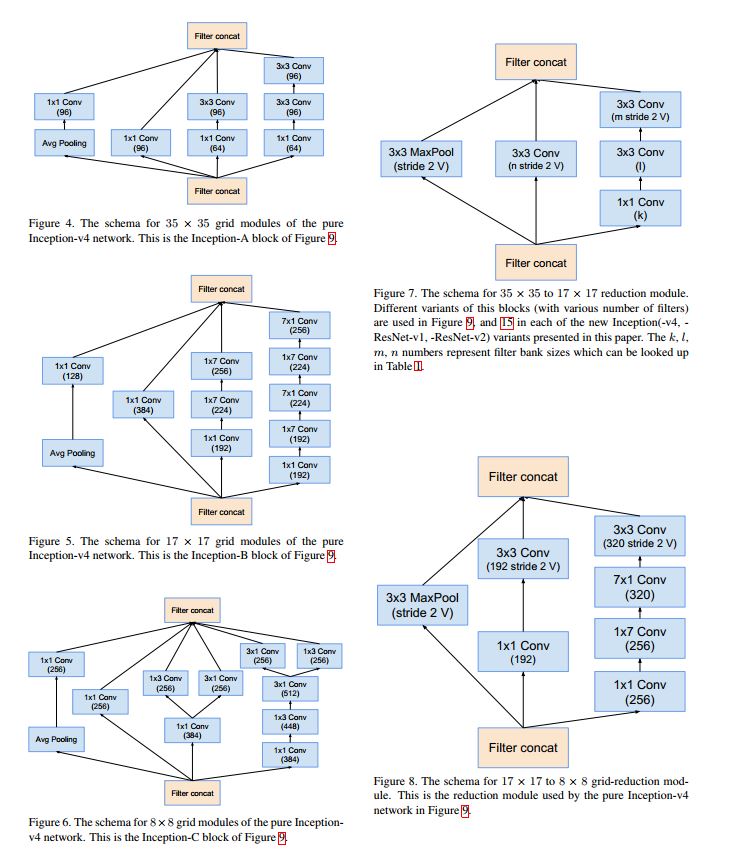
整体网络结构如下:

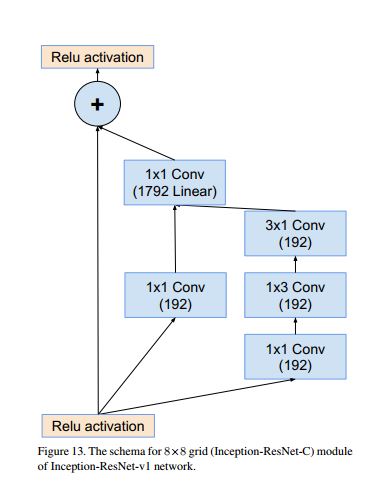
Inception-ResNet v1
结合了ResNet,结构如下:
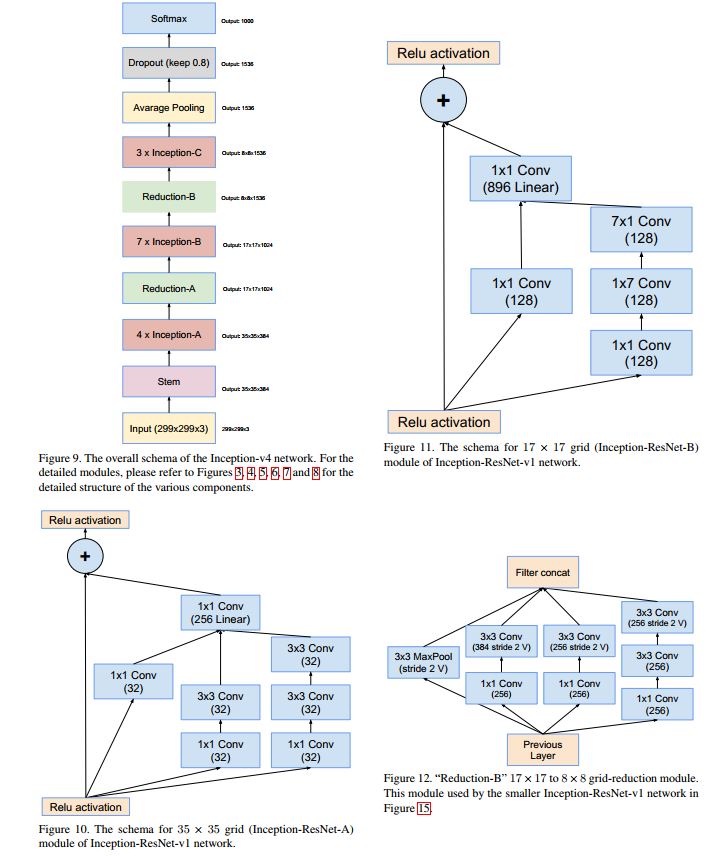
inception-resnet C模块如下:
Inception-ResNet v2
inception结构如下:
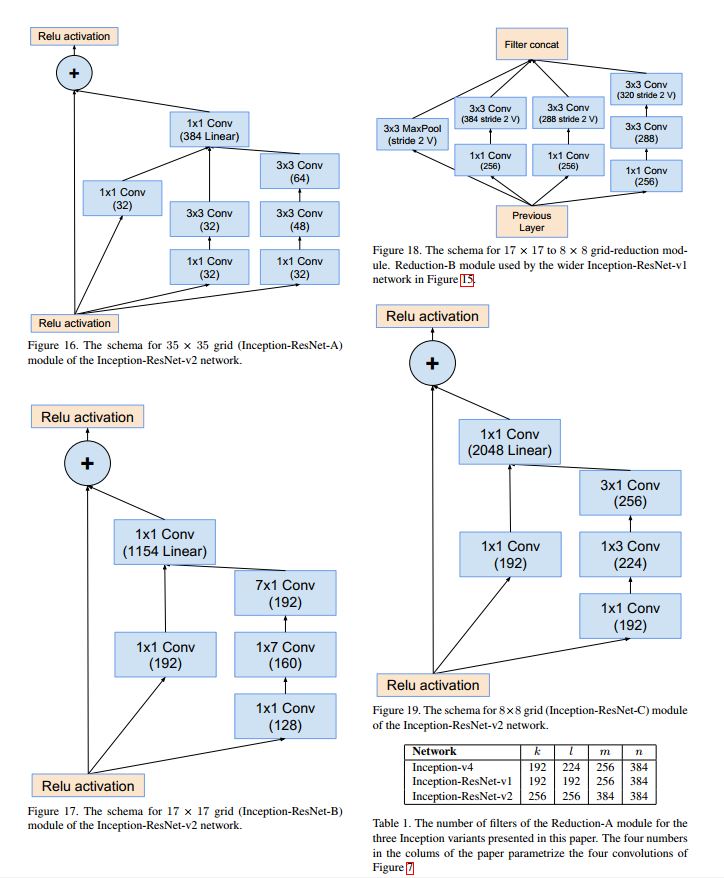
Inception-ResNet v1和v2整体网络结构如下:

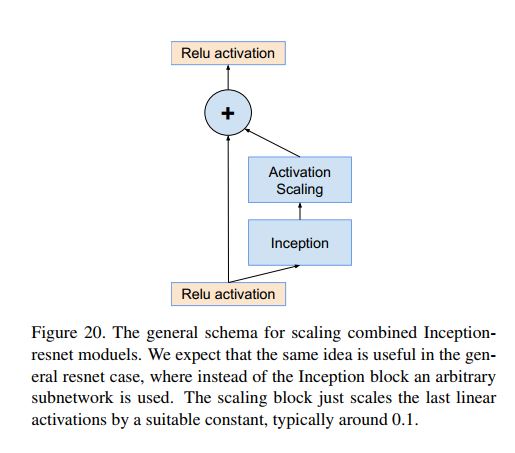
作者们实验发现如果对inception-resnet网络中的residual模块的输出进行scaling(如以0.1-0.3),那么可以让它的整个训练过程更加地稳定。如下图为scaling的具体做法示意。
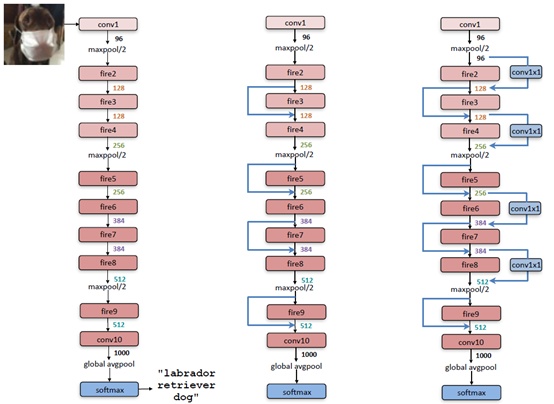
SqueezeNet – 2016
SqueezeNet是一种轻量级网络,参数比AlexNet少50x,但模型性能与AlexNet接近。
主要设计思想:
- 替换部分3×3的卷积为1×1卷积
- 减少输入3×3卷积的特征图数目(具体的通过设计Fire模块)
- 延迟下采样可以提升模型准确度(下采样方式一般为strides>1的卷积层或者池化层)
Fire模块结构如下:
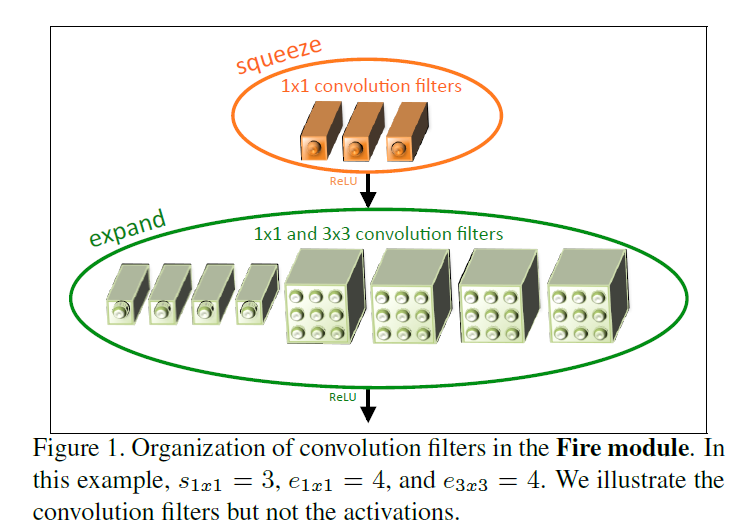
具体网络及引入了resnet的网络结构如下:
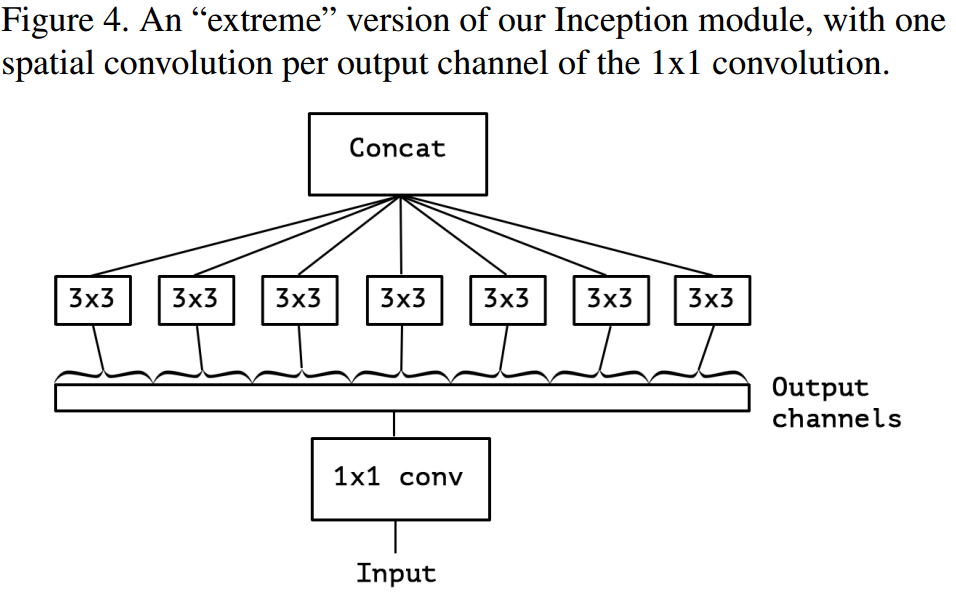
Xception – 2017
Xception模块如下:
Xception与原版的Depth-wise convolution有两个不同之处:
- 原版Depth-wise convolution先逐通道卷积,再1×1卷积;而Xception是反过来,先 1×1卷积,再逐通道卷积;
- 原版Depth-wise convolution的两个卷积之间是不带激活函数的,而Xception在经过1×1卷积之后会带上一个Relu的非线性激活函数;
整体网络结构如下:
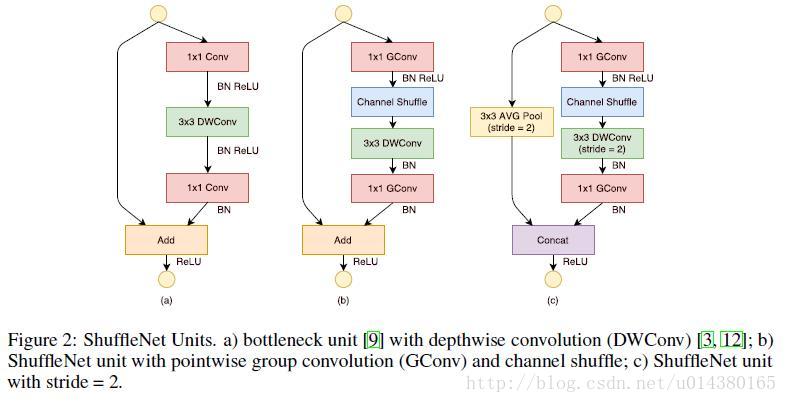
ShuffleNet – 2017
核心特点:
- channel shuffle
- pointwise group convolutions
- depthwise separable convolution
group convolutions和channel shuffle如下图所示:
pointwise group convolutions其实就是卷积核为1×1的group convolutions,depthwise separable convolution和MobileNet里面的一样。最终,修改后的ShuffleNet模块如下所示:
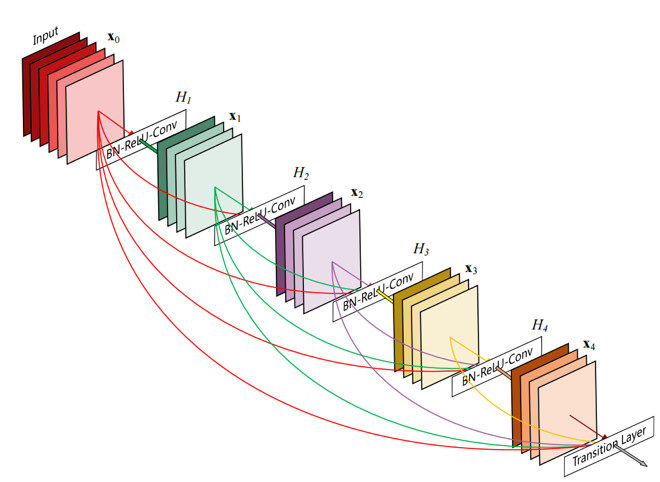
DenseNet – 2017
和resnet类似,每个DenseNet块如下图所示:
SENet – 2017
SENet模块如下所示:
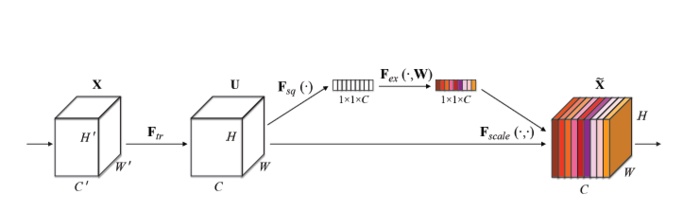
图中的$F_{tr}$是传统的卷积结构,X和U是$F_{tr}$的输入(C’xH’xW’)和输出(CxHxW),这些都是以往结构中已存在的。SENet增加的部分是U后的结构:对U先做一个Global Average Pooling(图中的$F_{sq}(\cdot)$,作者称为Squeeze过程),输出的1x1xC数据再经过两级全连接(图中的$F_{ex}(\cdot)$,作者称为Excitation过程),最后用sigmoid(论文中的self-gating mechanism)限制到[0,1]的范围,把这个值作为scale乘到U的C个通道上, 作为下一级的输入数据。这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
MobileNet V1 – 2017
主要提出了depthwise separable convolution(深度可分离卷积),主要分两部分:depthwise convolution和pointwise convolution,Depthwise convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。而pointwise convolution其实就是普通的卷积,只不过其采用1x1的卷积核。示意图如下:
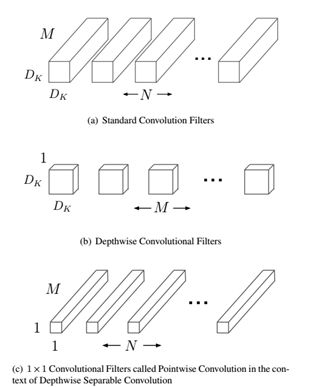
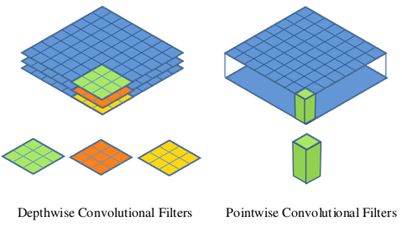
MobileNet V2 – 2018
主要结合了MobileNet V1和Shortcut connection(ResNet、DenseNet)的思想。
ResNeXt
网络模块的几种等价形式如下:
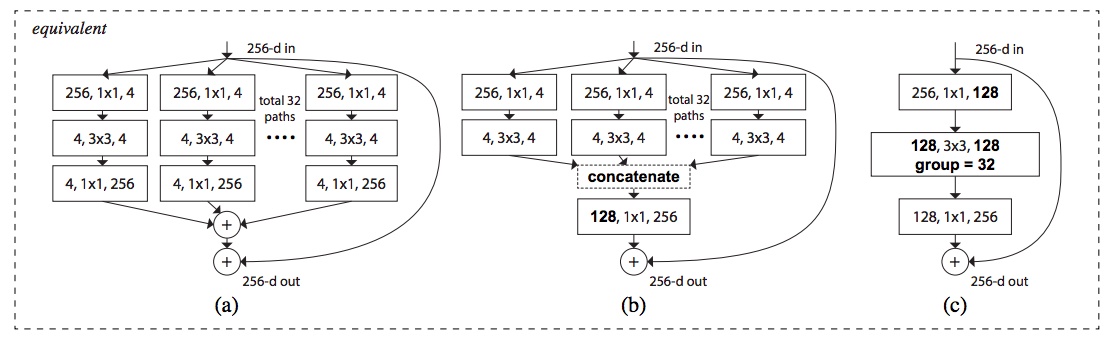
ResNext和Inception区别为:ResNext为相加,而Inception为级联。
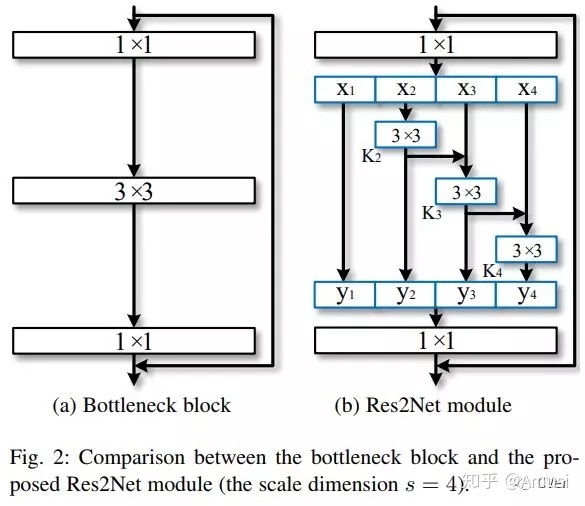
Res2Net
Res2Net模块如下:
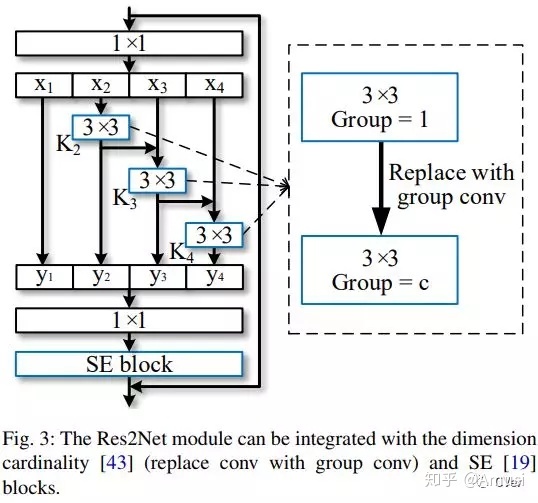
其中3×3的卷积可以替换成其他模块
MobileNet V3 – 2019
用了神经架构搜索,没有引入新的block,block继承自:
- MobileNetV1中的deepthwisse separable convolutions(深度可分离卷积)。
- MobileNetV2中的具有线性瓶颈的倒残差结构
- MnasNet(NasNet、MnasNet这种实在学不动啦~)中引入的基于squeeze and excitation结构的轻量级注意力模型

