CMake进阶之CMake原理与关键概念
版权声明:本文为CSDN博主「jupiterwangq」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ztemt_sw2/article/details/81384538
上一篇文章中我们通过一个很简单的示例项目展示了CMake构建脚本CMakeFileLists.txt的构成,我们初步认识了CMake中的一些概念:target(目标)、command(命令)等等。这篇文章我们来学习一下CMake的原理,并详细阐述这些概念。
1. CMake的结构
CMake有三个关键概念:target、generator和command,其中target和command我们已经有所了解了。在CMake中,这些东西本质上都是C++的类。理解这些概念对于编写出高效的CMake构建脚本很有帮助。
在更进一步了解CMake这些概念之前,有必要先了解一下target、generator和command之间的关系,一图胜千言:
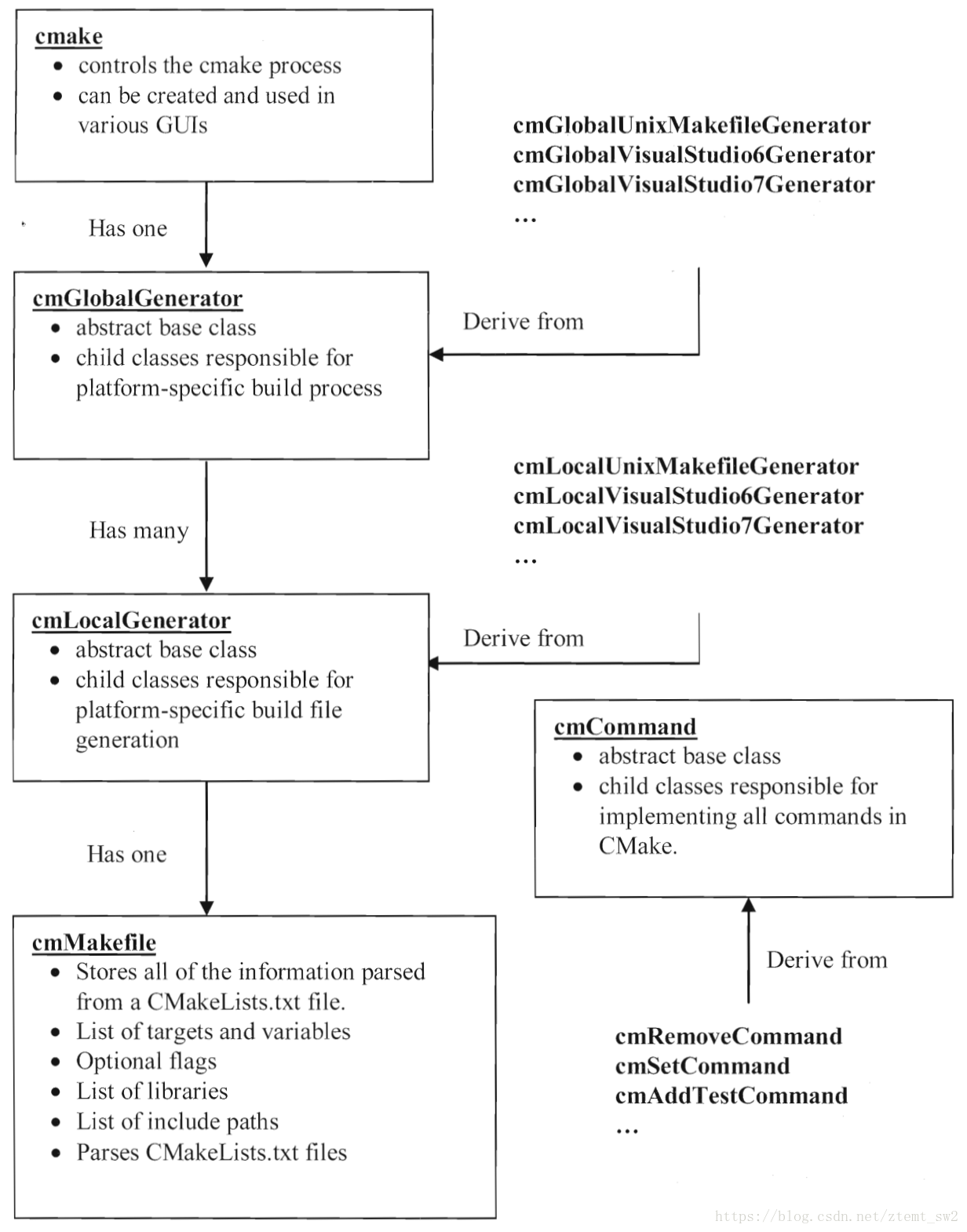 这张图够大够清晰,从《mastering cmake》中截取的,很好的描述了CMake主要组件关系:
这张图够大够清晰,从《mastering cmake》中截取的,很好的描述了CMake主要组件关系:
- cmake:控制cmake进程,可以在各种gui、命令行中创建和使用
- cmake持有一个cmGlobalGenerator的实例,cmGlobalGenerator是一个抽象基类,针对不同的平台有不同的子类:比如unix平台下的子类cmGlobalUnixMakeFileGenerator,微软vs的cmGlobalVisualStudio6Generator等。全局生成器的作用是负责特定平台的构建
- 全局生成器持有多个本地生成器cmLocalGenerator的实例,与cmGlobalGenerator类似,cmLocalGenerator也是抽象基类,有不同的子类去负责生成特定平台的构建文件。本地生成器对应于项目中各目录的CMakeFileLists.txt脚本
- 每一个localGenerator持有一个cmMakeFile实例,cmMakeFile解析并存储所有从CMakeFileLists.txt中解析出来的数据,包括target列表、所有的变量、依赖的库等等
- cmCommand:抽象基类,代表各种CMake命令的实现
CMake处理的最底层的东西就是若干个源代码文件,这些源代码文件被整合成一个或多个target,target一般情况下是一个可执行文件或者是库文件。对于源码目录树种的每一个目录,如果该目录中存在名为CMakeFileLists的构建脚本,并且有一个或多个target与之关联,则cmake会创建一个cmLocalGenerator的派生类(依据平台)为该目录生成特定平台的makefile或者项目构建文件。所有的local generator共享一个全局的global generator对象,这个全局global generator对象有cmake创建并管理。
2. CMake的运行原理
我们已经了解了构成CMake的一些主要的组件以及他们之间的关系,接下来更详细的说明CMake的运行原理。
当我们在命令行输入:cmake ../Test这样一条命令的时候,一个cmake对象会被创建出来,命令行参数传入该对象。cmake对象管理整个项目的配置,并且持有构建过程需要用到的一些全局信息(比如缓存值)。cmake对象首先要做的事情之一就是创建一个全局生成器对象(cmGlobalGenerator的子类),然后调用该对象的相关方法,传入必要的参数。
全局生成器负责配置并生成项目所有的Makefile(或者工程文件),当然全局生成器是通过创建若干个本地生成器(localGenerator),然后把工作委托给本地生成器来完成这项艰巨任务的。对于项目中每一个包含CMakeFileLists脚本的目录,全局生成器都会创建一个本地生成器来生成对应的目录的构建文件。
绝大多数工作其实是由本地生成器去做的,例如类Unix平台上,cmake会创建出cmGlobalUnixMakefileGenerator全局生成器,对于每个目录,全局生成器生成cmLocalUnixMakefileGenerator本地生成器,由它去解析目录中的CMakefileLists脚本,并生成makefile或其他特定于平台的文件。全局生成器要做的主要是将各个loacal generator的工作收集起来生成一个最顶层的Makefile。
每个本地生成器都会创建并持有一个cmMakefile对象,cmMakefile解析CMakefileLists脚本,并存储解析到的数据。因为一个cmMakefile对应项目中的一个目录(确切的说应该是包含CMakefileLists脚本的目录),因此cmMakefile对象有时候也用目录来称呼。可以把cmMakefile理解成是一个由父目录用相关参数初始化的对象,然后在解析CMakefileLists脚本的过程中逐渐向其中填充各种数据。
最后再来看看command,上一篇文章我们已经看到了许多的CMake命令(find_library,set,target_link_libraries等等),在CMake中每个命令都对应一个C++的类。每个命令对象主要有两个关键方法:
InitialPass,该方法以命令参数以及当前处理的目录对应的cmMakefile对象的实例 为参数,然后执行相应的操作。以set (Foo a)这个命令为例,该命令会调用传入的cmMakefile对象的相关方法给变量设定值,命令的执行结果通常也是存放在cmMakefile对象中。
command对象的另一个主要方法是FinalPass,当所有的命令的InitialPass执行完以后,会调用这个方法。绝大多数命令都不实现这个方法,只有极少数的情况才会用到。
一旦项目中所有的CMakefileLists构建脚本处理完毕,生成器就会用已经存放在cmMakefile实例中的信息去生成目标构建系统(例如make或者visual studio)上需要的文件。
3. 详解target
target顾名思义就是cmake最终要生成的目标,一般情况下就是可执行文件和库。通过下面三条命令都可以生成一个目标:
add_library:生成一个库目标add_executable:生成一个可执行目标add_custom_target:生成一个自定义目标,这个用途也很大,我们在后续文章中在单独详细说明
我们以add_library为例,上一篇文章已经看到过它的魅影,这里更详细的认识一下这个命令:
add_library (foo, STATIC, foo.c)
这条命令将生成一个名为foo的静态库目标,有了这条命令,foo这个名字就可以作为库名在你的项目中的任何地方使用。库通常是STATIC,SHARED和MODULE三种类型之一,STATIC表明生成的是一个静态库,类似的SHARED为共享库,MOUDLEB表明生成的库可以被可执行文件动态加载。除了mac os x系统外,SHARED和MODULE作用是相同的。如果使用add_library命令时不指定类型,则cmake会根据BUILD_SHARED_LIBS变量的值来确定是编译出SHARED库还是STATIC库,如果BUILD_SHARED_LIBS也没有指定,则默认编译出STATIC库。
类似的,add_executable命令也有一些选项,默认的情况下cmake会生成一个带有main函数的控制台应用程序,如果在可执行目标名的后面指定了WIN32,则该命令将生成一个win32应用程序,其入口为WinMain,在非windows的平台上,WIN32选项不起任何作用。
除了类型以为,target还持有一些通用的属性,这些属性可以通过set_target_property和get_target_property访问。这些属性中最常见的是LINK_FLAGS,用来为待生成的目标指定链接选项。 target要链接的库可以通过target_link_libraries,这个上一篇文章的示例程序也已经看到过。
对于每一个生成的库,cmake都会跟踪该库所依赖的其他库,举个例子就清楚这话是什么意思了,假设有如下命令:
add_library (foo foo.c)
target_link_libraries (foo bar)
add_executable (foobar foobar.cpp)
target_link_libraries (foobar foo)
首先添加了一个库目标foo,然后foo这个库依赖于另外一个库bar,因此用target_link_libraries链接之。然后添加了一个可执行目标foobar,注意上面的代码中,只给改可执行目标链接了foo库,但是cmake知道foo库链接了bar库,因此虽然我们没有写显示指定,但是cmake会自动给可执行目标foobar链接上bar库。
4. 变量和缓存
4.1 变量以及作用域
和其他编程语言一样,CMAKE中也有变量的概念,用来把值存起来以备后用。变量可以只有一个值,也可以拥有一组值(想象成数组)除了自定义的变量外,CMAKE已经内置了一些很有用的变量。
变量通过set命令定义,值得注意的是CMAKE中的变量也是有作用域的,来看个例子:
set (foo 1) #定义变量foo,值为1
add_subdirectory (dir1) #处理子目录dir1,之前定义的变量foo被传入子目录的生成器中,并且值为1
set (bar 2) #定义变量bar,值为2,注意此时dir1中看不到此变量
add_subdirectory (dir2) #处理子目录dir2,变量foo和bar都会被传入到dir2的生成器中,因此在该目录下两个变量均可见。
再来看一个关于CMAKE中变量作用域的例子:
function (foo) #定义一个函数foo
message (${test}) #输出变量test的值
set (test 2) #将变量test的值设置为2
message (${test}) #变量的值为2
endfunction(foo) #函数结束
set (test 1) #将变量test的值设置为1
foo () #调用函数
message (${test}}) #打印变量test的值,此时仍旧为1
注意到上面这个例子中,定义了一个函数foo,函数调用前test的值为1,然后在foo函数中将变量test的值置为2,可以看到函数调用结束以后变量的值仍旧为1,也就是说函数foo中对变量的改变仅限于函数内部,这有点类似于C语言中以传值的方式给函数传递参数,此时相当于变量被拷贝了一份传递给函数。
那如果想让函数中对变量的改变在函数外部也生效呢?可以把函数改成下面这样:
function (foo) #定义一个函数foo
message (${test}) #输出变量test的值
set (test 2 PARENT_SCOPE) #将变量test的值设置为2
message (${test}) #变量的值为2
endfunction() #函数结束
注意到函数中在设置值时,set命令多了一个PARENT_SCOPE,表示此次的改变在变量的父作用域中也生效,这样当函数调用完以后,值就变成新值2了。
这里顺便说一下cmake中function与macro的区别:
# function有独立的作用域,内部定义的变量外部无法访问
function(build_variable)
set(NEW_VAR 1)
endfunction(build_variable)
build_variable()
message(STATUS "NEW_VAR: ${NEW_VAR}") # -- NEW_VAR:
# macro则是宏定义,macro中定义的变量都在当前scope中
macro(macro_build_var)
set(MACRO_VAR 1)
endmacro(macro_build_var)
macro_build_var()
message(STATUS "MACRO_VAR: ${MACRO_VAR}") # -- MACRO_VAR: 1
4.2 缓存
我们经常会遇到这种情况:有些变量的值想让用户在构建的时候自己去做选择,缓存变量(cache entry)可以满足我们的需求。我们运行CMAKE的时候,CMAKE都会在构建目录下生成一个缓存文件,这个缓存文件中的值将会显示在cmake gui中。缓存的目的有两个:
(1) 将用户的选择缓存下来,这样用户之后不论何时启动cmake,他们不必重新去输入这些值。
通过option命令可以就可以创建一个缓存变量并存放在缓存文件中:
option (USE_JPEG "Do you want to use the jpeg library")
上面这个option命令帮我们生成一个USE_JPEG缓存变量,当用户运行cmake-gui时,就可以通过ui设置变量的值。
有3中方式来创建一个缓存变量:
option命令、find_file命令以及set命令,用set命令生成缓存变量时,只需要加一个CACHE就可以了,像下面这样:
set (USE_JPEG ON CACHE BOOL "Do you want to use the jpeg library")
和一般的set命令不同,需要指定变量的类型,并且用CACHE告诉CMAKE这是一个缓存变量。
(2) 使用缓存变量的另外一个原因是:有些变量的值确定起来非常耗时,比如一些系统相关的变量如字节序,为了确定字节序,CMAKE必须要编译并且运行一小段程序才能确定,对于这种代价比较高的变量,同时值确定以后不会怎么变的,将它缓存起来是一个不错的主意。
除了单一的值以外,有时候可能想提供一组值让用户选择,可以通过给缓存变量提供STRINGS属性达成此目的。参考下面的代码段:
#定义一个类型为STRING的缓存变量
set (CRYPTOBACKEND "OpenSSL" CACHE STRING "Select a crypto backend" )
#给缓存变量CRYPTOBACKEND设置属性STRINGS,指定三个值作为选项
set_property (CACHE CRYPTOBACKEND PROPERTY STRINGS "OpenSSL" "LibTomCrypt" "LibDES")
加入这段代码以后,运行cmake-gui,会在界面上看到一个下拉选择菜单,让用户选择值。
最后一点:缓存的值在CMAKE中是可以覆盖的。通过不带CACHE选项的set命令,就可以覆盖缓存变量的值。注意覆盖以后,缓存中变量的值不会改变,只有当前目录以及子目录中的值会被覆盖。
例如有一个缓存变量foo,缓存中的值是1,然后在顶层的CMakefileLists文件中通过set命令改写了它的值:
set (foo 2)
这样当前目录及所有子目录中该变量的值均为2,但是缓存中依旧为1。
5. CMAKE构建配置
CMAKE通过配置可以构建出不同的软件,默认的情况下CMKAE支持四种构建配置:
Debug:CMKAE会打开一些基本的调试开关进行构建Release:CMAKE在构建时会打开一些基本的优化选项开关MinSizeRel:CMAKE会使构建出的目标代码体积尽可能小,但不一定是最优最快的RelWithDebInfo:CMKAE构建出带有调试信息并且经过编译优化后的版本
CMAKE会根据具体的生成器进行处理(就是之前提到的cmUnixMakefileGenerator,cmVisualStudioGenerator等),一般情况下CMAKE会尽量遵守原生构建系统的规则。
对于visual studio,可以通过变量CMAKE_CONFIGURATION_TYPE告诉CMAKE工程应该使用哪种配置,而基于makefile类型的生成器,可以通过CMAKE_BUILD_TYPE来指定配置类型。
6. 小结
本文我们了解了cmake的一些主要组件以及其运行的原理。
- 介绍了cmake的主要组件以及其运行原理;
- 介绍了cmake的变量,包括缓存变量,以及变量的作用域;
理解cmake的运行原理有助于我们写出更高效的cmake构建脚本,可以结合项目实践来加深对相关概念的理解。

