CNN Models
ResNet
参考至ResNet解析
参考至ResNet结构分析
ResNet结构

两种残差块(residual block):

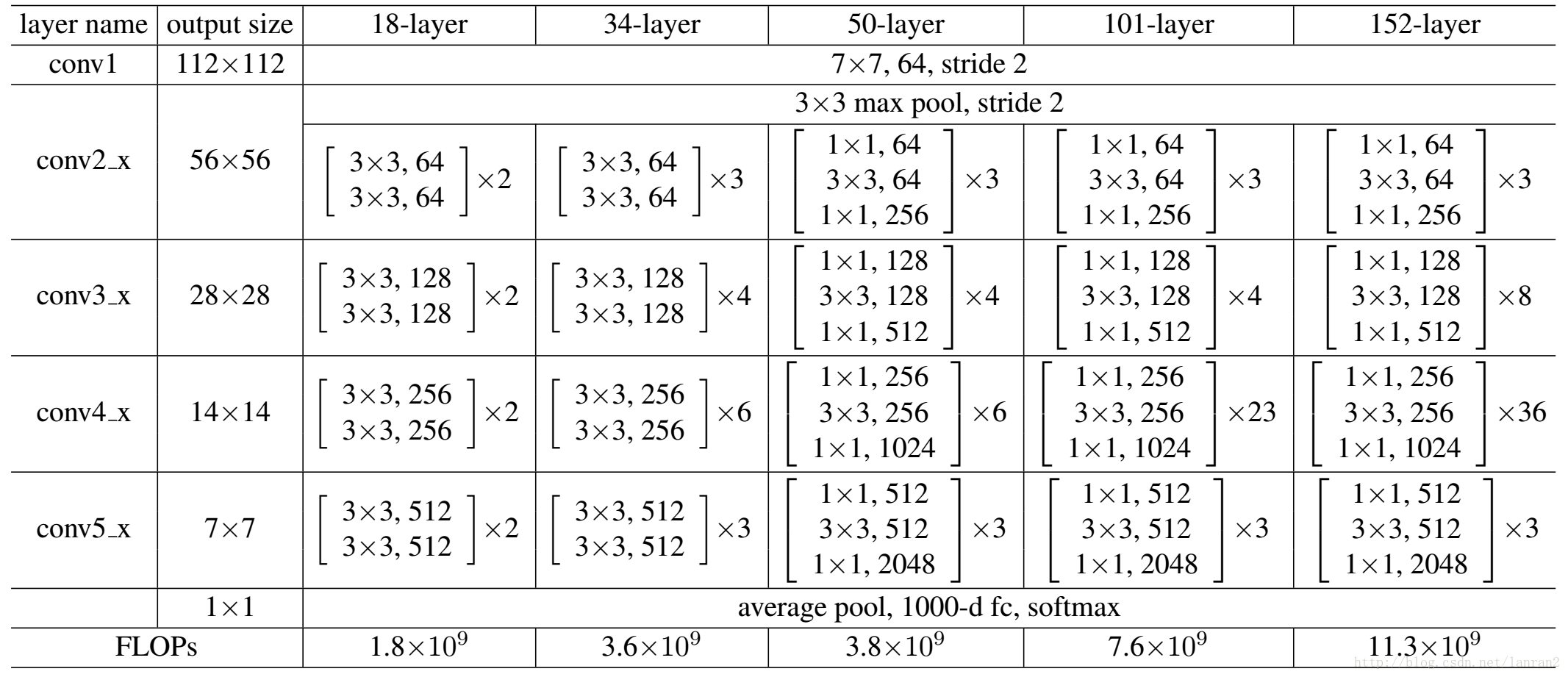
对于常规ResNet(fig2. (a)),可以用于34层或者更少的网络中,对于Bottleneck Design(fig2. (b))的ResNet通常用于更深的如50/101/152这样的网络中,目的是减少计算次数和参数量。具体来说,右边的bottleNeck先用一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体计算量为:
\(1\times1\times256\times64+3\times3\times64\times64+1\times1\times64\times256=69632\)
参数数目为:
\(1\times1\times64+3\times3\times64+1\times1\times256=896\)
对于左边basicBlock,若输入channel同样为256时,整体计算量为:
\(3\times3\times256\times256+3\times3\times256\times256=1179648\)
参数数目为:
\(3\times3\times256+3\times3\times256=4608\)
由于$F(x)$与$x$是按照channel维度相加的,网络中存在$F(x)$与$x$的channel个数不同的情况,因此需根据channel个数分为两种情况:
channel相同:
\(y=F(x)+x\)
channel不同:
\(y=F(x)+Wx\)
其中引入$1\times1$的卷积核$W$对$x$进行卷积操作,来调整$x$的channel维度。
不同层数下的ResNet结构如下图所示:
ResNet-V2
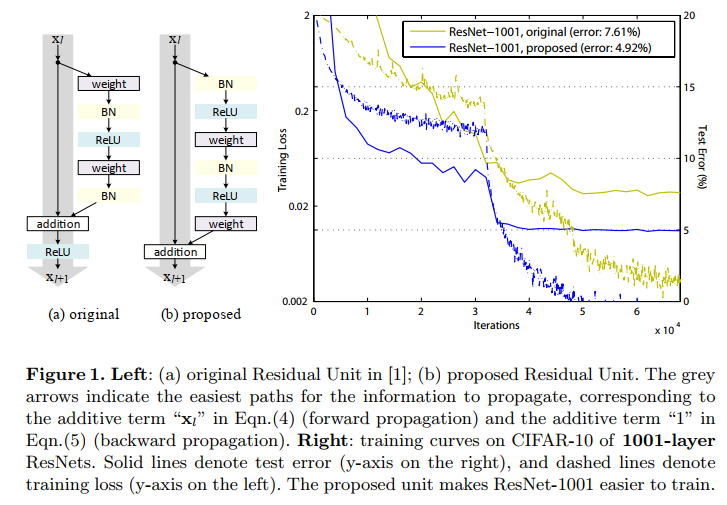
fig1. resnetV1(左) VS resnetV2(右)(residual block区别)
weight -> $W$ -> conv2D
如图所示,ResNetV1与ResNetV2最大的区别在于残差块中BN/activation的位置:
ResNet-V1:
- conv -> BN -> activation
- 最后的activation在addition后面
ResNet-V2:
- BN -> activation -> conv
这样做的优势:
- 模型优化更加容易
相比于原始的网络结构,先激活的网络中的f是恒等变换 - 减少网络的过拟合
作者分析这可能是BN层的作用,在原始网络中,虽然残差函数的输出被归一化了,但是这个归一化的结果与残差块的输入直接相加作为下一个残差块的输入,这个输入在与权重层相乘之前并没有被归一化;而在先激活的网络中,输入与权重层相乘之前都被归一化了,所以有着更好的性能。
MobileNet
MobileNet的基本单元是深度可分离卷积(depthwise separable convolution),其实这种结构之前已经被使用在Inception模型中。
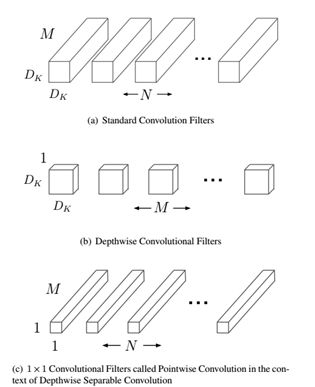
fig1. Depthwise separable convolution
如fig.1所示,深度可分离卷积可以分解为两个更小的操作:
- depthwise convolution($DW$层)
- pointwise convolution($PW$层)
Depthwise convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。而pointwise convolution其实就是普通的卷积,只不过其采用1x1的卷积核。
- 首先采用depthwise convolution对不同输入通道分别进行卷积
- 然后采用pointwise convolution将上面的输出再进行结合
这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
直观上来看,这种分解在效果上确实是等价的。比如,把上图的代号化为实际的数字,输入图片维度是11 × 11 × 3,标准卷积为3 × 3 × 3 ×16(假设stride为2,padding为1),那么可以得到输出为6 × 6 × 16的输出结果。现在输入图片不变,先通过一个维度是3 × 3 × 1 × 3的深度卷积(输入是3通道,这里有3个卷积核,对应着进行计算,理解成for循环),得到6 × 6 × 3的中间输出,然后再通过一个维度是1 × 1 × 3 ×16的1 ×1卷积,同样得到输出为6 × 6 × 16。
计算量分析
这里简单分析一下depthwise separable convolution在计算量上与标准卷积的差别。假定输入特征图大小是$D_F \times D_F \times M$,而输出特征图大小是$D_F \times D_F \times N$,其中$D_F$是特征图的width和height,这是假定两者是相同的,而和指的是通道数(channels or depth)。这里也假定输入与输出特征图大小(width and height)是一致的。采用的卷积核大小是尽管是特例,但是不影响下面分析的一般性。对于标准的卷积$D_K \times D_K$,其计算量将是:
\(D_K \times D_K \times M \times N \times D_F \times D_F\)
而对于depthwise convolution其计算量为:$D_K\times D_K\times M\times D_F\times D_F$,pointwise convolution计算量是:$M\times N \times D_F\times D_F$,所以depthwise separable convolution总计算量是:
\(D_K\times D_K\times M\times D_F\times D_F+M\times N \times D_F\times D_F\)
可以比较depthwise separable convolution和标准卷积如下:
\(\frac{D_K\times D_K\times M\times D_F\times D_F+M\times N \times D_F\times D_F} {D_K \times D_K \times M \times N \times D_F \times D_F} = \frac1 N+\frac1 {D^2_K}\)
一般情况下$N$比较大,那么如果采用3x3卷积核的话,depthwise separable convolution相较标准卷积可以降低大约9倍的计算量。其实,后面会有对比,参数量也会减少很多。
参数量计算
MobileNet网络结构
前面讲述了depthwise separable convolution,这是MobileNet的基本组件,但是在真正应用中会加入batchnorm,并使用ReLU激活函数,所以depthwise separable convolution的基本结构如fig.2所示。
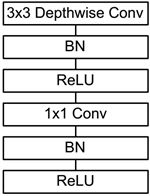
fig2. 实际depthwise separable convolution结构
MobileNet的网络结构如fig3.所示。首先是一个3x3的标准卷积,然后后面就是堆积depthwise separable convolution,并且可以看到其中的部分depthwise convolution会通过strides=2进行down sampling。然后采用average pooling将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。如果单独计算depthwise
convolution和pointwise convolution,整个网络有28层(这里Avg Pool和Softmax不计算在内)。
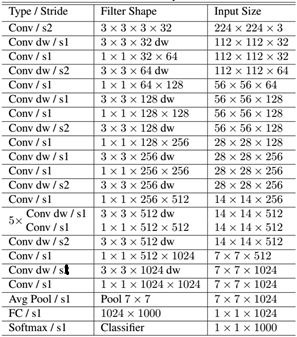
fig3. MobileNet网络结构
我们还可以分析整个网络的参数和计算量分布,如fig4.所示。可以看到整个计算量基本集中在1x1卷积上,如果你熟悉卷积底层实现的话,你应该知道卷积一般通过一种im2col方式实现,其需要内存重组,但是当卷积核为1x1时,其实就不需要这种操作了,底层可以有更快的实现。对于参数也主要集中在1x1卷积,除此之外还有就是全连接层占了一部分参数。
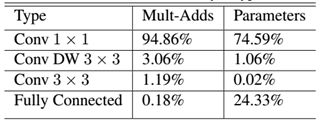
fig4. MobileNet网络计算量与参数分步
MobileNet-v2
参考至MobileNet V2 论文初读
参考至小小将GitHub, 知乎
MobileNet网络是Google提出主要应用在移动端的轻量级CNN网络。目前,Google公开了更高效的MobileNet-v2。
相比于MobileNet:
- v2依然使用v1中的深度可分离卷积(depthwise separable convolution),
- v2新引入了残差结构和bottleneck层,这种新的结构称为Bottleneck residual block
Relu6
首先说明一下ReLU6,卷积之后通常会接一个ReLU非线性激活,在Mobile v1里面使用ReLU6,ReLU6就是普通的ReLU但是限制最大输出值为6(对输出值做clip),这是为了在移动端设备float16的低精度的时候,也能有很好的数值分辨率,如果对ReLU的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失。
本文提出,最后输出的ReLU6去掉,直接线性输出,理由是:ReLU变换后保留非0区域对应于一个线性变换,仅当输入低维时ReLU能保留所有完整信息。
Xception已经实验证明了Depthwise卷积后再加ReLU效果会变差,作者猜想可能是Depthwise输出太浅了应用ReLU会带来信息丢失,而MobileNet还引用了Xception的论文,但是在Depthwise卷积后面还是加了ReLU。在MobileNet v2这个ReLU终于去掉了(非紧邻,最后的ReLU),并用了大量的篇幅来说明为什么要去掉(各种很复杂的证明,你不会想自己推一遍的= =,从理论上说明了去掉ReLU的合理性)。
对比MobileNet v1与v2的微结构
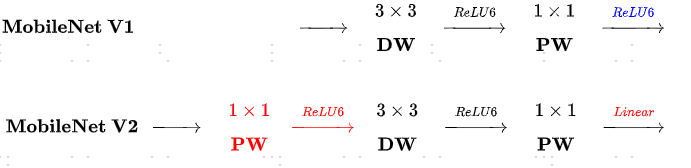
相同点
- 都采用Depth-wise($DW$)卷积搭配Point-wise($PW$)卷积的方式来提特征。这两个操作合起来也被称为 Depth-wise Separable Convolution,之前在 Xception 中被广泛使用。这么做的好处是理论上可以成倍的减少卷积层的时间复杂度和空间复杂度。由下式可知,因为卷积核的尺寸$D_K$通常远小于输出通道数$N$,因此标准卷积的计算复杂度近似为$DW+PW$组合卷积的$D_K^2$倍(证明)。
不同点:Linera Bottleneck
- V2 在$DW$卷积之前新加了一个$PW$卷积。这么做的原因,是因为$DW$卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。所以如果上一层给的通道数本身很少的话, $DW$也只能很委屈的在低维空间提特征,因此效果不够好。现在V2为了改善这个问题,给每个$DW$之前都配备了一个$PW$,专门用来升维,默认升维系数$t=6$,这样不管输入通道数$M$是多是少,经过第一个$PW$升维之后,$DW$都是在相对的更高维($t*M$)进行工作。
- V2去掉了第二个$PW$的激活函数。论文作者称其为 Linear Bottleneck。这么做的原因,是因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。由于第二个$PW$的主要功能就是降维,因此按照上面的理论,降维之后就不宜再使用ReLU6了。
MobileNet v2网络结构

fig1. Bottleneck residual block的内部构成
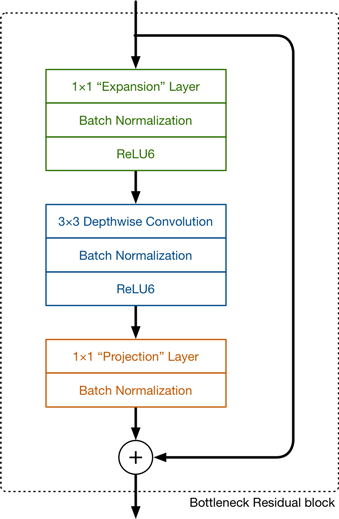
fig2. Bottleneck residual block示意图
如fig3.所示,正常的residual bottleneck(fig.3(a))一般先采用bottleneck layer进行降纬,最后进行扩展;而这里使用的bottleneck位置恰恰相反,paper里面称这种相反的残差block为inverted residual block。采用这种结构的优势如下:
- 这种结果可以在实现上减少内存的使用
- 这种相反的结构从实验结果上也更好一点
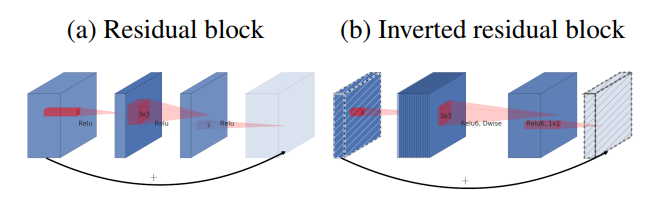
fig3. inverted residual block和residual block之间的对比
将block堆积起来,就形成最终的MobileNetv2网络,各个block设计如fig4.所示,其中t是扩展比,c是block的输出特征的channel大小,n是block的重复次数,s是stride,注意只有对于重复的block只有开始的s才是2。另外与MobileNetv1类似,v2也设计了width multiplier和输入大小两个超参数控制网络的参数量,表2中默认的是width multiplier=1.0,输入大小是224x224。输入大小影响的是特征图空间大小,而width multiplier影响的是特征图channel大小。输入大小可以从96到224,而width multiplier可以从0.35到1.4。值得注意的一点是当width multiplier小于1时,不对最后一个卷积层的channel进行调整以保证性能,即维持1280。
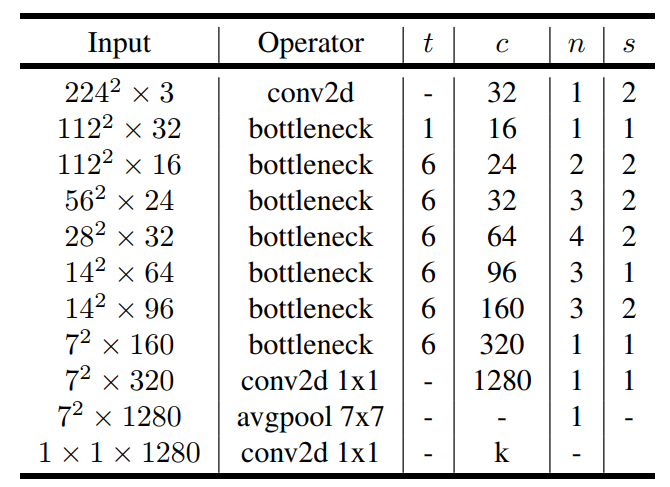
fig4. MobileNet v2的网络结构
DeepFace
参考至FaceBook的DeepFace网络(博客)
DeepFace输入为152*152的图像,网络结构如下:
- Conv:32个11×11×3的卷积核
- max-pooling: 3×3, stride=2
- Conv: 16个9×9的卷积核
- Local-Conv: 16个9×9的卷积核,Local的意思是卷积核的参数不共享
- Local-Conv: 16个7×7的卷积核,参数不共享
- Local-Conv: 16个5×5的卷积核,参数不共享
- Fully-connected: 4096维
- Softmax: 4030维
前三层的目的在于提取低层次的特征,比如简单的边和纹理。其中Max-pooling层使得卷积的输出对微小的偏移情况更加鲁棒。但没有用太多的Max-pooling层,因为太多的Max-pooling层会使得网络损失图像信息。 后面三层都是使用参数不共享的卷积核,之所以使用参数不共享,有如下原因:
- 对齐的人脸图片中,不同的区域会有不同的统计特征,卷积的局部稳定性假设并不存在,所以使用相同的卷积核会导致信息的丢失
- 不共享的卷积核并不增加抽取特征时的计算量,而会增加训练时的计算量
- 使用不共享的卷积核,需要训练的参数量大大增加,因而需要很大的数据量,然而这个条件本文刚好满足。
全连接层将上一层的每个单元和本层的所有单元相连,用来捕捉人脸图像不同位置的特征之间的相关性。其中,第7层(4096-d)被用来表示人脸。 全连接层的输出可以用于Softmax的输入,Softmax层用于分类。

